Prometheus+Grafana全方位监控Kubernetes集群
文章目录
[toc]
1.k8s监控指标
kubernetes本身监控
- Node资源利用率
- Node数量
- Pods数量
- 资源对象状态
Pod监控
- pod数量
- 容器资源利用率
- 应用程序
实现思路
- pod性能
- 使用cadvisor进行实现,监控容器的CPU、内存利用率
- Node性能
- 使用node-exporter实现,主要监控节点CPU、内存利用率
- K8S资源对象
- 使用kube-state-metrics实现,主要用于监控pod、deployment、service
k8s服务发现参考文档: https://prometheus.io/docs/prometheus/latest/configuration/configuration/#kubernetes_sd_config
本文将会实现k8s全方位监控,并配合grafana展示k8s资源对象的使用状态,以及配合alertmanager告警
2.k8s基础环境准备
2.1.环境准备
| IP | 角色 |
|---|---|
| 192.168.16.106 | k8s-master |
| 192.168.16.104 | k8s-node1 |
| 192.168.16.107 | k8s-node2 |
| 192.168.16.105 | nfs |
2.2.部署nfs作为prometheus存储
[root@nfs ~]\# mkdir /data/prometheus
[root@nfs ~]\# yum -y install nfs-utils
[root@nfs ~]\# vim /etc/exports
/data/prometheus 192.168.16.0/24(rw,sync,no_root_squash)
[root@nfs ~]\# systemctl restart nfs
[root@nfs ~]\# showmount -e
Export list for nfs:
/data/prometheus 192.168.16.0/24
[root@nfs ~]\# chomd -R 777 /data
2.3.获取prometheus yaml文件
在这里下载
https://github.com/kubernetes/kubernetes/tree/release-1.16/cluster/addons/prometheus
直接克隆完整目录也可以
https://github.com/kubernetes/kubernetes.git
⚠️修改:https://gitlab.com/AGou-ops/k8s_prometheus_yaml.git
prometheus在github的k8s目录中master分支已经找不到了,可以在release-1.16这里找到
1.拉取prometheus yaml文件
[root@k8s-master ~/k8s]\# git clone https://github.com/kubernetes/kubernetes.git
2.将prometheus yaml文件复制到其他目录
[root@k8s-master ~/k8s]\# cp -rp kubernetes/cluster/addons/prometheus/ .
本人的yaml文件
官方yaml文件

文件说明
主要分为四部分:prometheus部署、alertmanager部署、kube-state-metrics部署、node-exporter部署
| 文件名 | 作用 |
|---|---|
| alertmanager-configmap.yaml | alertmanager配置集合的yaml文件 |
| alertmanager-deployment.yaml | alertmanager创建pod的yaml文件 |
| alertmanager-pvc.yaml | alertmanager挂载存储卷的yaml文件 |
| alertmanager-service.yaml | alertmanager对外暴露端口的yaml文件 |
| grafana_pv_pvc.yaml | grafana挂载存储卷的yaml文件 |
| grafana_statefulset.yaml | grafana发布pod的yaml文件,采用statefulset资源 |
| grafana_svc.yaml | grafana对外暴露端口的yaml文件 |
| install_node_exportes.sh | 批量在node节点安装node_exporter的脚本 |
| k8s_time.yaml | k8s同步宿主机时间的yaml文件 |
| kube-state-metrics-deployment.yaml | k8s采集资源状态指标程序的yaml文件 |
| kube-state-metrics-rbac.yaml | 8s采集程序授权的yaml文件 |
| kube-state-metrics-service.yaml | k8s采集程序对外暴露的yaml文件 |
| node-exporter-ds.yml | node_exporter部署的yaml文件 |
| node-exporter-service.yaml | node_exporter对外暴露的yaml文件 |
| prometheus-configmap.yaml | prometheus的配置文件集 |
| prometheus-pv-pvc.yaml | prometheus挂载存储的yaml文件 |
| prometheus-rbac.yaml | prometheus授权访问api的yaml文件 |
| prometheus-rules-pvc.yaml | prometheus告警规则存储卷的yaml文件 |
| prometheus-rules.yaml | prometheus将rule做成cm资源的yaml文件 |
| prometheus-service.yaml | prometheus对外提供访问的yaml文件 |
| prometheus-statefulset-static-pv.yaml | prometheus程序部署的yaml文件 |
2.4.创建命名空间prometheus
创建一个ns为prometheus,将除了kube-state-metrics外的yaml中的namespace修改为prometheus
1.创建ns
[root@k8s-master ~/k8s/prometheus]\# kubectl create namespace prometheus
namespace/prometheus created
2.修改
用vim打开输入以下命令
:%s/namespace: kube-system/namespace: prometheus/g
3.在k8s中部署prometheus
3.1.prometheus-yaml准备
主要用到以下几个yaml
[root@k8s-master ~/k8s/prometheus]\# ls prometheus-*
prometheus-configmap.yaml prometheus-rbac.yaml prometheus-service.yaml prometheus-statefulset.yaml
创建顺序
先创建prometheus-rbac.yaml
在创建prometheus-configmap.yaml
在创建prometheus-statefulset.yaml
最后创建prometheus-service.yaml
3.2.创建rbac资源
[root@k8s-master ~/k8s/prometheus]\# kubectl create -f prometheus-rbac.yaml
serviceaccount/prometheus created
clusterrole.rbac.authorization.k8s.io/prometheus created
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
3.3.创建configmap资源
[root@k8s-master ~/k8s/prometheus]\# kubectl create -f prometheus-configmap.yaml
configmap/prometheus-config created
3.4.创建statefulset资源
github上的statefulset资源使用的是storageclasee动态创建pv,由于不会使用storageclass,因此将statefulset资源进行改造,使用静态pv做存储
3.4.1.改造statefulst资源支持静态pv
改造思路:在yaml中增加pv、pvc的配置,在将原来的storageclass配置项删除,在120行的volume中增加pvc的配置即可
[root@k8s-master ~/k8s/prometheus]\# vim prometheus-statefulset-static-pv.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: prometheus-data
namespace: prometheus
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 16Gi
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-prometheus
spec:
capacity:
storage: 16Gi
accessModes:
- ReadWriteOnce
nfs:
path: /data/prometheus/prometheus_data
server: 192.168.16.105
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: prometheus
namespace: kube-system
labels:
k8s-app: prometheus
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
version: v2.2.1
spec:
serviceName: "prometheus"
replicas: 1
podManagementPolicy: "Parallel"
updateStrategy:
type: "RollingUpdate"
selector:
matchLabels:
k8s-app: prometheus
template:
metadata:
labels:
k8s-app: prometheus
spec:
priorityClassName: system-cluster-critical
serviceAccountName: prometheus
initContainers:
- name: "init-chown-data"
image: "busybox:latest"
imagePullPolicy: "IfNotPresent"
command: ["chown", "-R", "65534:65534", "/data"]
volumeMounts:
- name: prometheus-data
mountPath: /data
subPath: ""
containers:
- name: prometheus-server-configmap-reload
image: "jimmidyson/configmap-reload:v0.1"
imagePullPolicy: "IfNotPresent"
args:
- --volume-dir=/etc/config
- --webhook-url=http://127.0.0.1:9090/-/reload
volumeMounts:
- name: config-volume
mountPath: /etc/config
readOnly: true
resources:
limits:
cpu: 10m
memory: 10Mi
requests:
cpu: 10m
memory: 10Mi
- name: prometheus-server
image: "prom/prometheus:v2.23.0"
imagePullPolicy: "IfNotPresent"
args:
- --config.file=/etc/config/prometheus.yml
- --storage.tsdb.path=/data
- --web.console.libraries=/etc/prometheus/console_libraries
- --web.console.templates=/etc/prometheus/consoles
- --web.enable-lifecycle
ports:
- containerPort: 9090
readinessProbe:
httpGet:
path: /-/ready
port: 9090
initialDelaySeconds: 30
timeoutSeconds: 30
livenessProbe:
httpGet:
path: /-/healthy
port: 9090
initialDelaySeconds: 30
timeoutSeconds: 30
# based on 10 running nodes with 30 pods each
resources:
limits:
cpu: 200m
memory: 1000Mi
requests:
cpu: 200m
memory: 1000Mi
volumeMounts:
- name: config-volume
mountPath: /etc/config
- name: prometheus-data
mountPath: /data
subPath: ""
terminationGracePeriodSeconds: 300
volumes:
- name: config-volume
configMap:
name: prometheus-config
- name: prometheus-data
persistentVolumeClaim:
claimName: prometheus-data
3.4.2.创建statefulset资源
[root@k8s-master ~/k8s/prometheus]\# kubectl create -f prometheus-statefulset-static-pv.yaml
persistentvolumeclaim/prometheus-data created
persistentvolume/pv-prometheus created
statefulset.apps/prometheus created
3.5.创建service资源
3.5.1.修改service资源支持nodeport
[root@k8s-master ~/k8s/prometheus]\# vim prometheus-service.yaml
kind: Service
apiVersion: v1
metadata:
name: prometheus
namespace: prometheus
labels:
kubernetes.io/name: "Prometheus"
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
type: NodePort
ports:
- name: http
port: 9090
protocol: TCP
targetPort: 9090
selector:
k8s-app: prometheus
3.5.2.创建service资源
[root@k8s-master ~/k8s/prometheus]\# kubectl create -f prometheus-service.yaml
service/prometheus created
3.6.查看创建的prometheus所有资源类型
[root@k8s-master ~/k8s/prometheus]\# kubectl get pod,svc,pv,pvc -n prometheus -o wide

主要访问30387端口看到prometheus
3.7.访问prometheus
使用任意node节点的ip加30387端口即可访问:http://192.168.16.106:30387/
查看监控主机
可以看到已经有很多了,这些配置都是configmap资源中配置的
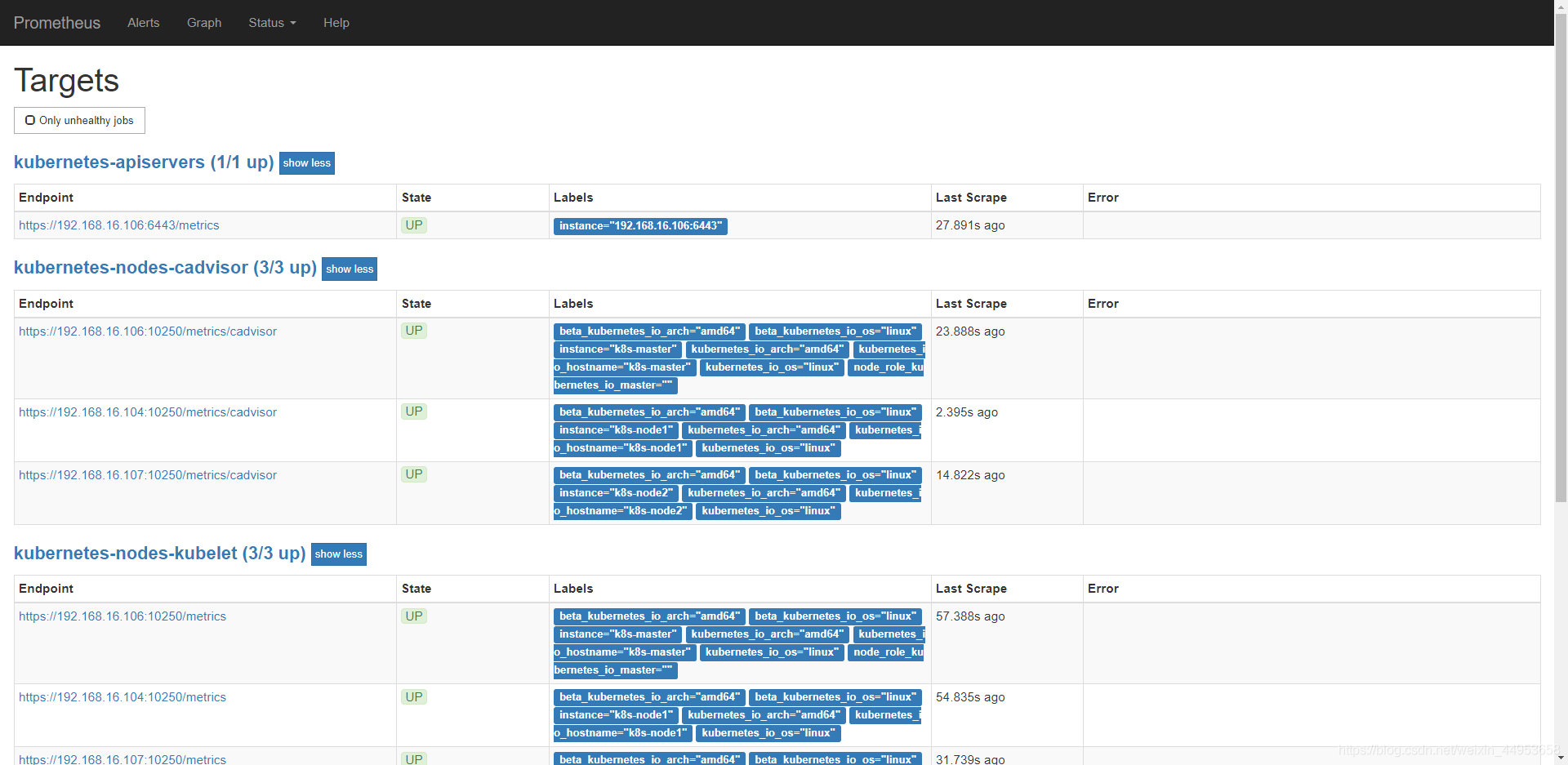
3.8.prometheus配置文件解释
3.8.1.进入prometheus容器
语法:kubectl exec -it pod名 进入的环境 -c 容器名称 -n 命名空间
[root@k8s-master ~/k8s/prometheus]\# kubectl exec -it prometheus-0 sh -c prometheus-server -n prometheus
/prometheus $
配置文件位于:/etc/config/prometheus.yml
tsdb存储位于:/data
3.8.2.配置文件解释
/prometheus $ more /etc/config/prometheus.yml
scrape_configs:
- job_name: prometheus
static_configs:
- targets:
- localhost:9090
静态配置,将本机加到了prometheus监控,这个localhost就是运行prometheus容器的地址
kubernetes-apiservers自动发现
将apiserver的地址进行暴露并获取监控指标
- job_name: kubernetes-apiservers
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: keep
regex: default;kubernetes;https
source_labels:
- __meta_kubernetes_namespace
- __meta_kubernetes_service_name
- __meta_kubernetes_endpoint_port_name
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token

k8s的node节点自动发现
自动发现k8s中的所有node节点并进行监控
- job_name: kubernetes-nodes-cadvisor
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __metrics_path__
replacement: /metrics/cadvisor
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token

发现endpoint的资源
主要是发现endpoint资源类型的pod,可以通过kubectl get ep查看谁是endpoint资源
- job_name: kubernetes-service-endpoints
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scrape
- action: replace
regex: (https?)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scheme
target_label: __scheme__
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_service_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_service_name
target_label: kubernetes_name

发现services
- job_name: kubernetes-services
kubernetes_sd_configs:
- role: service
metrics_path: /probe
params:
module:
- http_2xx
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_probe
- source_labels:
- __address__
target_label: __param_target
- replacement: blackbox
target_label: __address__
- source_labels:
- __param_target
target_label: instance
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- source_labels:
- __meta_kubernetes_service_name
target_label: kubernetes_name
发现pod
- job_name: kubernetes-pods
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scrape
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_pod_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: kubernetes_pod_name
3.9.k8s metrics页面
metrics页面访问如下也没关系,metrics貌似只能集群内部进行访问
只要能在prometheus搜索到container数据就可以
4.在k8s中部署grafana
4.1.编写granfana-pv-pvc资源
1.编写资源
[root@k8s-master ~/k8s/prometheus3]\# vim grafana_pv_pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana-ui-data
namespace: grafana-ui
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-grafana-ui-data
namespace: grafana-ui
spec:
capacity:
storage: 3Gi
accessModes:
- ReadWriteOnce
nfs:
path: /data/prometheus/grafana
server: 192.168.16.105
2.在nfs上创建对应的挂载点
[root@nfs ~]\# mkdir /data/prometheus/grafana
4.2.编写granfana-statefulset资源
[root@k8s-master ~/k8s/prometheus3]\# vim grafana_statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: grafana-ui
namespace: grafana-ui
spec:
serviceName: "grafana-ui"
replicas: 1
selector:
matchLabels:
app: grafana-ui
template:
metadata:
labels:
app: grafana-ui
spec:
containers:
- name: grafana-ui
image: grafana/grafana:6.6.2
imagePullPolicy: "IfNotPresent"
ports:
- containerPort: 3000
protocol: TCP
resources:
limits:
cpu: 100m
memory: 256Mi
requests:
cpu: 100m
memory: 256Mi
volumeMounts:
- name: grafana-ui-data
mountPath: /var/lib/grafana
subPath: ""
securityContext:
fsGroup: 472
runAsUser: 472
volumes:
- name: grafana-ui-data
persistentVolumeClaim:
claimName: grafana-ui-data
4.3.编写granfana-svc资源
[root@k8s-master ~/k8s/prometheus3]\# vim grafana_svc.yaml
apiVersion: v1
kind: Service
metadata:
name: grafana-ui
namespace: grafana-ui
spec:
type: NodePort
ports:
- name: http
port: 3000
protocol: TCP
targetPort: 3000
selector:
app: grafana-ui
4.4.k8s创建grafana
[root@k8s-master ~/k8s/prometheus3]\# kubectl create -f grafana_pv_pvc.yaml
persistentvolumeclaim "grafana-ui-data" created
persistentvolume "pv-grafana-ui-data" created
[root@k8s-master ~/k8s/prometheus3]\# kubectl create -f prometheus-statefulset-static-pv.yaml
persistentvolumeclaim/prometheus-data created
persistentvolume/pv-prometheus created
statefulset.apps/prometheus created
[root@k8s-master ~/k8s/prometheus3]\# kubectl create -f grafana_svc.yaml
service/grafana-ui created
4.5.查看资源运行状态
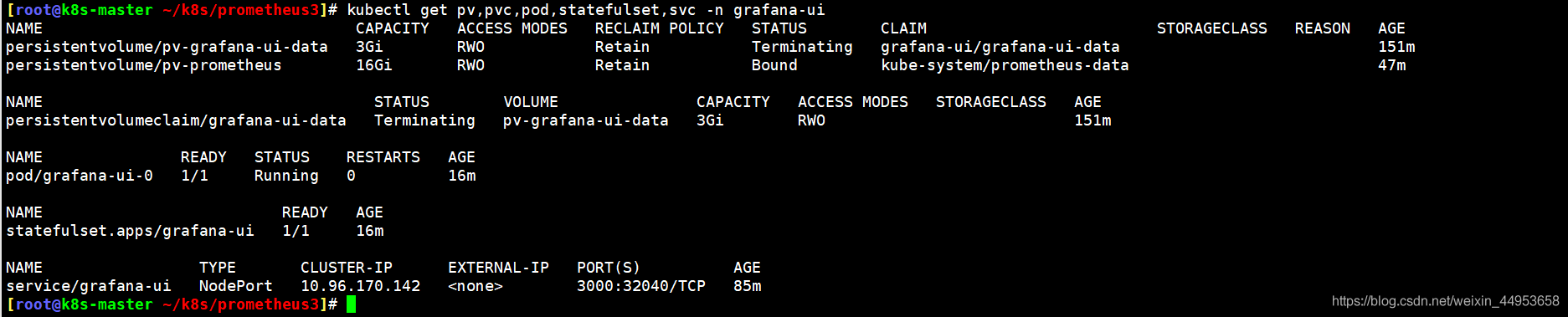
[root@k8s-master ~/k8s/prometheus3]\# kubectl get pv,pvc,pod,statefulset,svc -n grafana-ui
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pv-grafana-ui-data 3Gi RWO Retain Terminating grafana-ui/grafana-ui-data 151m
persistentvolume/pv-prometheus 16Gi RWO Retain Bound kube-system/prometheus-data 47m
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/grafana-ui-data Terminating pv-grafana-ui-data 3Gi RWO 151m
NAME READY STATUS RESTARTS AGE
pod/grafana-ui-0 1/1 Running 0 16m
NAME READY AGE
statefulset.apps/grafana-ui 1/1 16m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/grafana-ui NodePort 10.96.170.142 <none> 3000:32040/TCP 85m
4.6.登陆grafana
访问:集群任意ip和32040端口即可访问
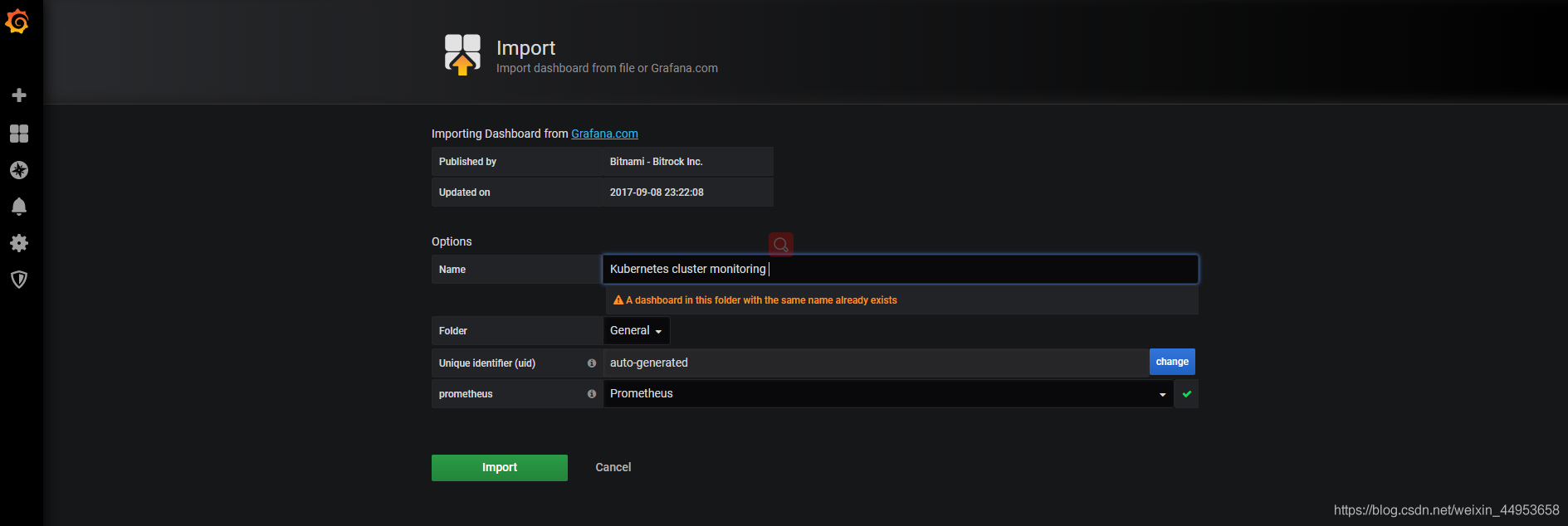
4.7.导入k8s资源监控pod资源模板
推荐模板:
- 集群资源监控:3119
- 资源状态监控:6417
- node监控:9276
导入成功
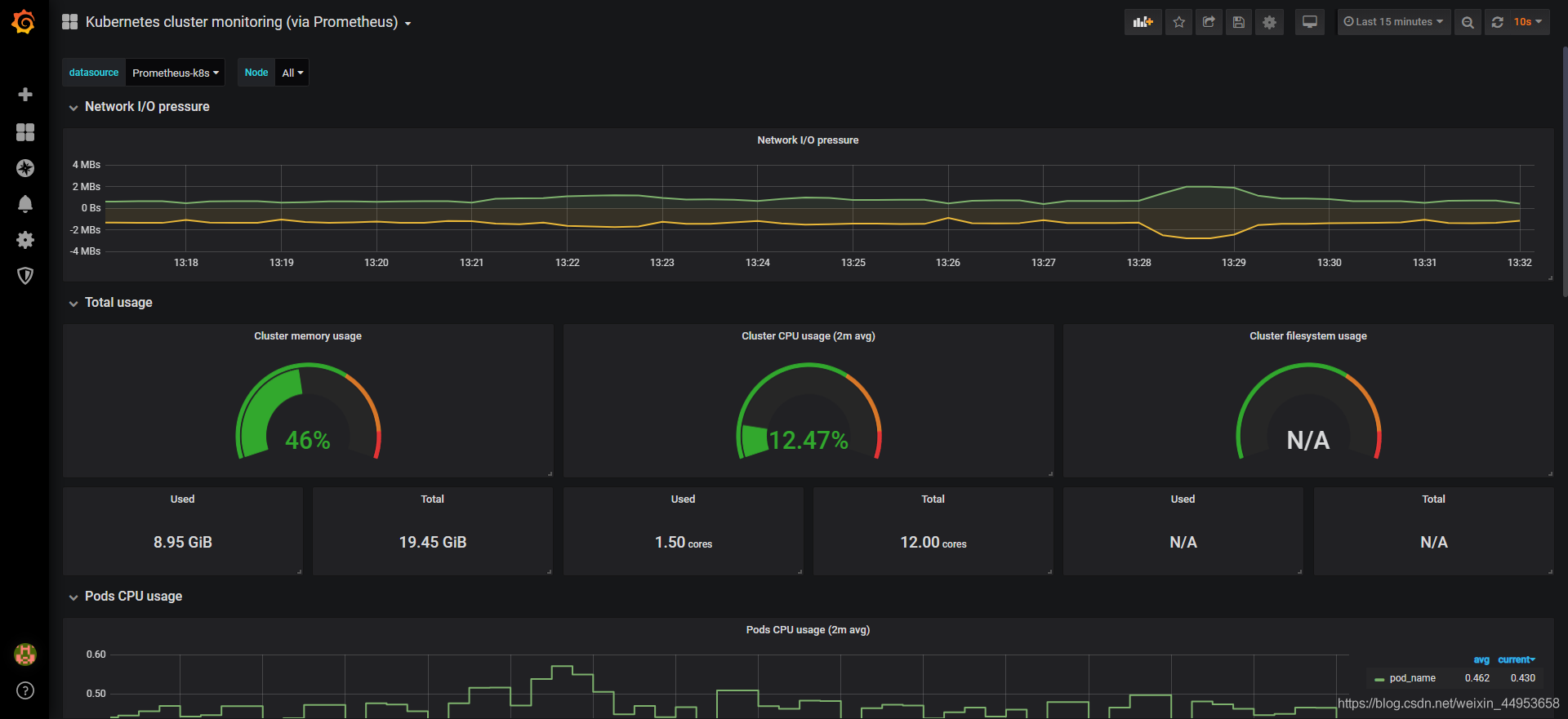
4.8.解决模板表达式问题无法展现所有pod
4.8.1.问题描述
模板中的图形关于pod和docker的全部有问题,仅单单显示一个pod
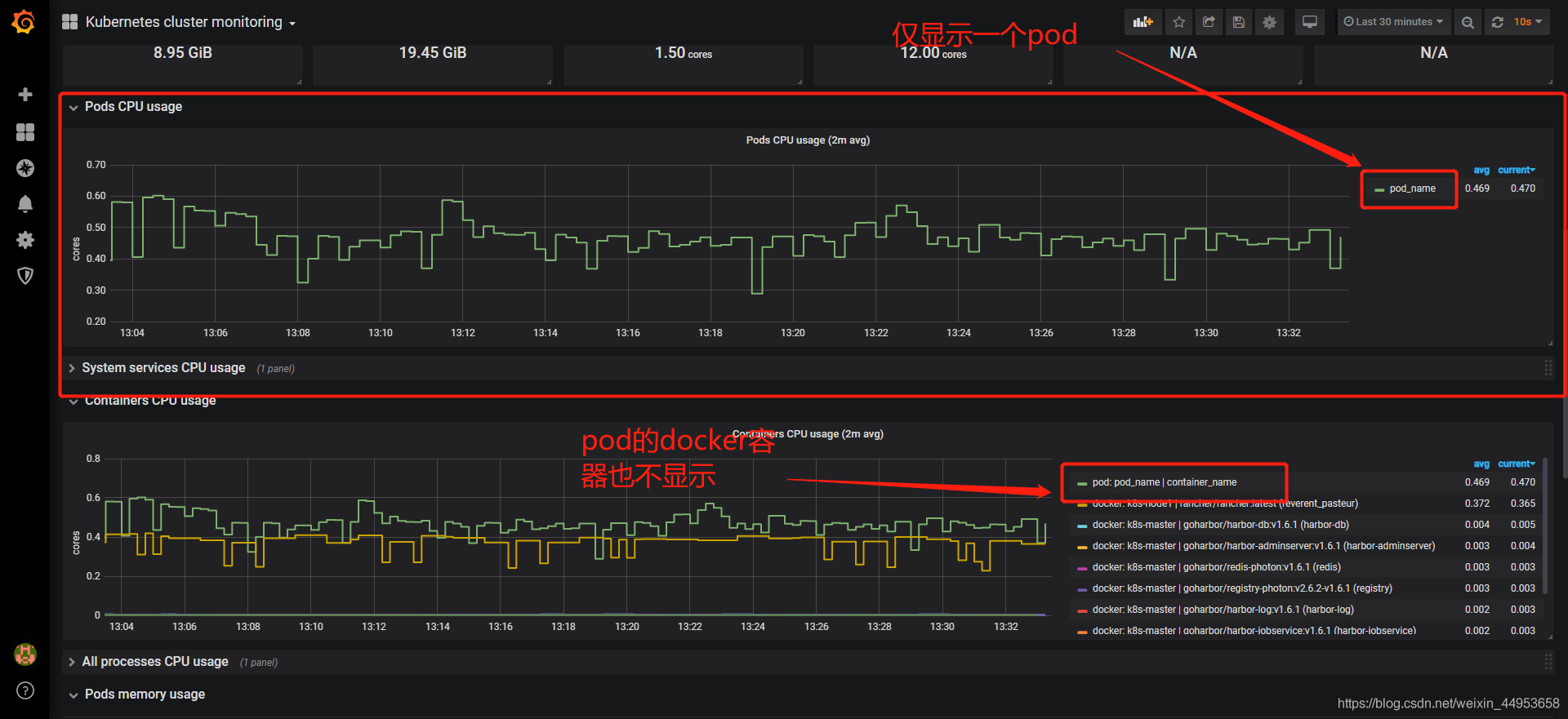
4.8.2.问题解决
修改他们的表达式就可以了,将pod_name修改为pod
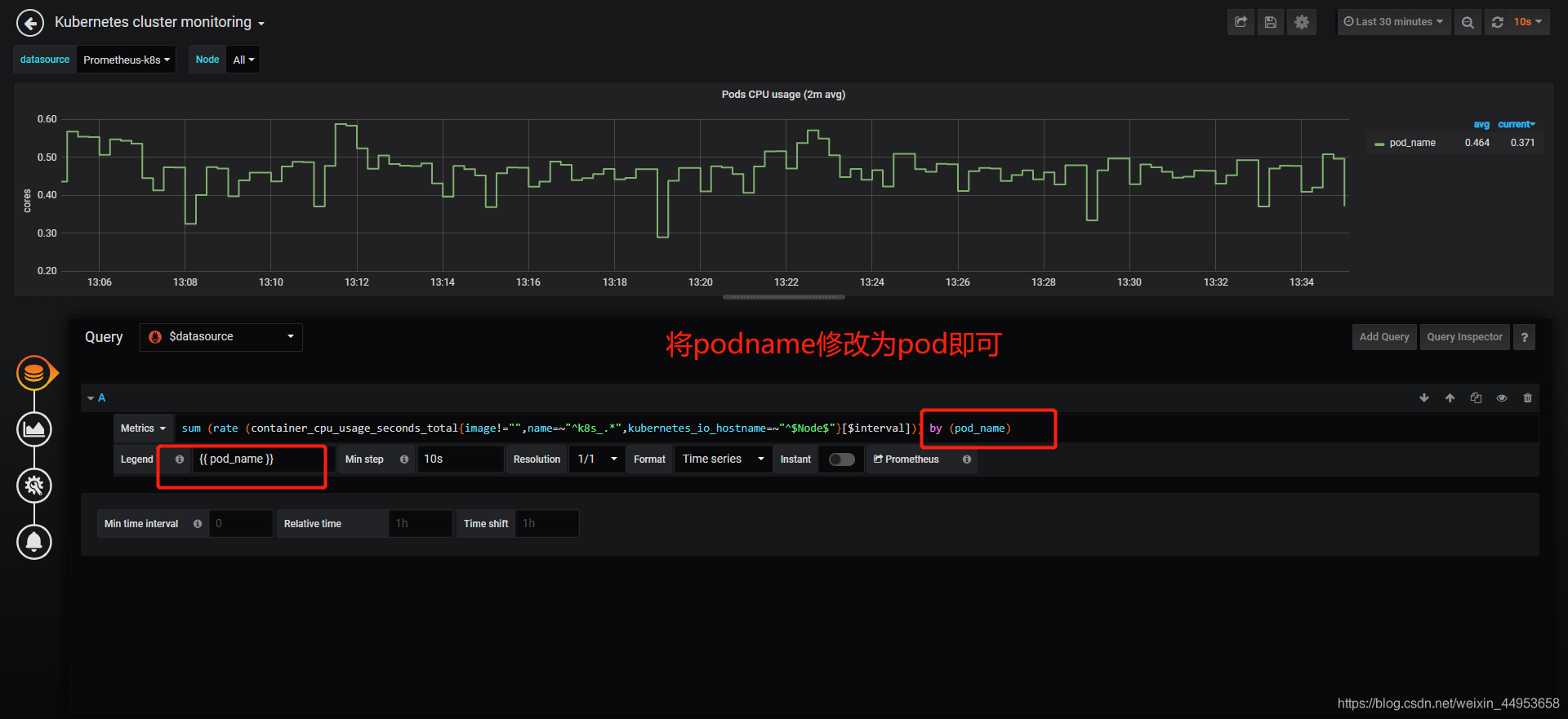
修改为立马显示出所有pod,所有关于pod和docker的都是这么改
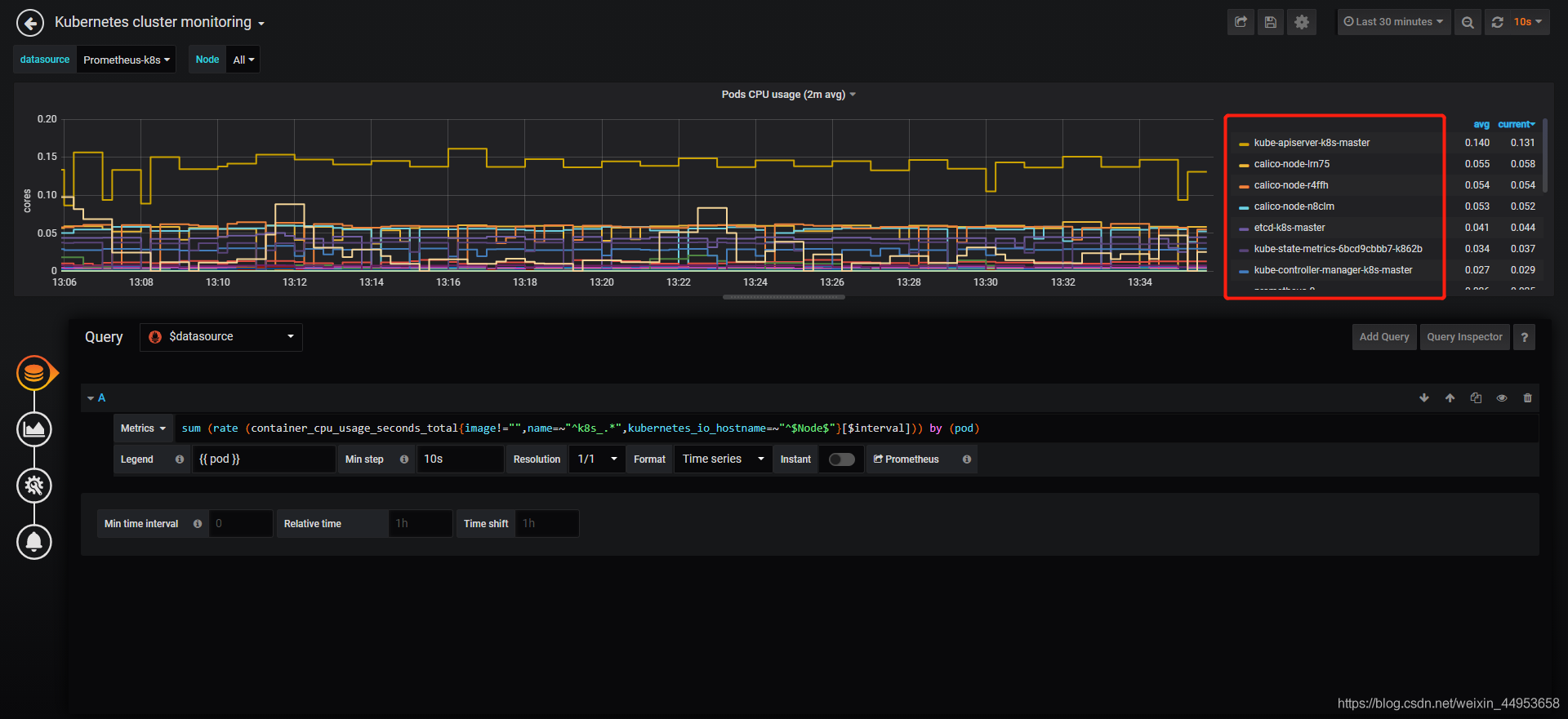
最终展示效果
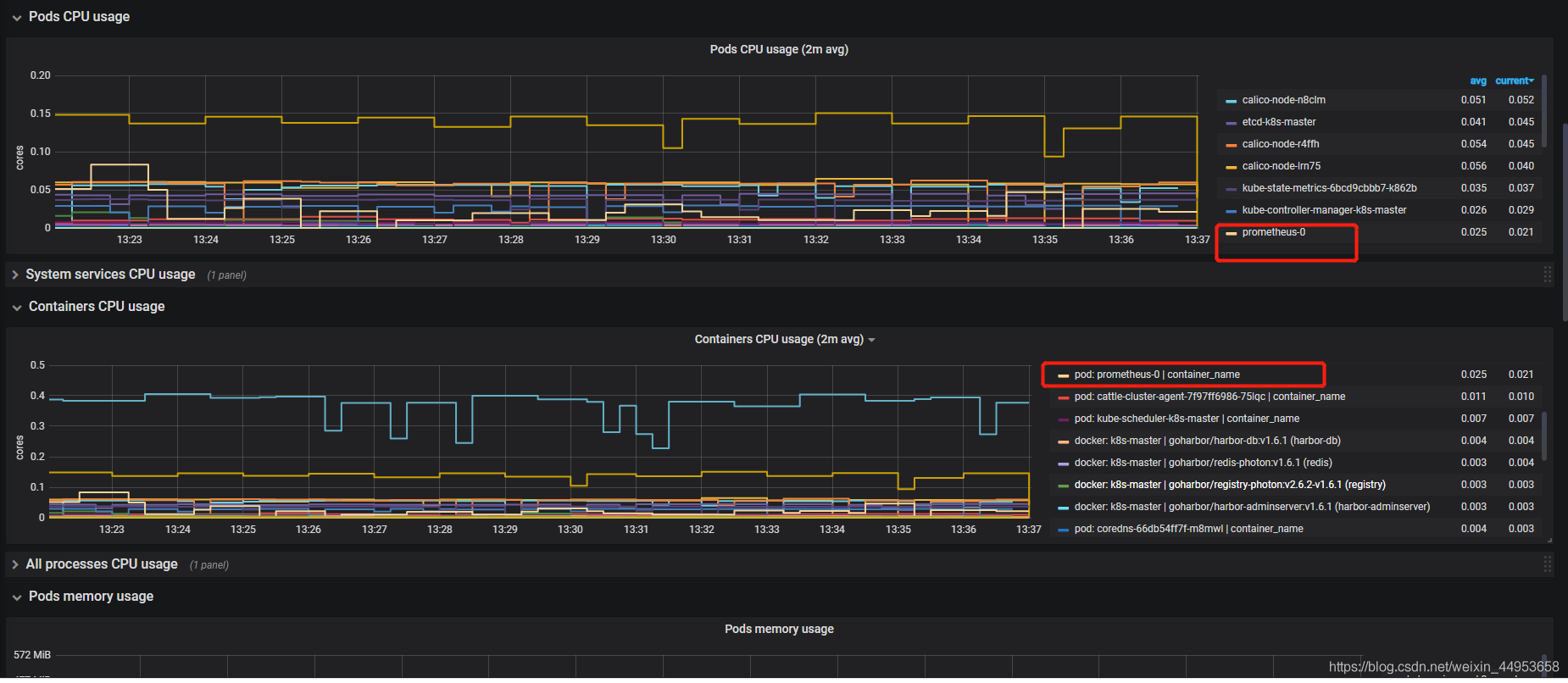
5.监控k8s node节点
对于node节点的监控我们不用部署在k8s里,直接在每台node机器上安装node_exporter即可
5.1.编写一键部署node_exporter脚本
[root@k8s-master ~/k8s/prometheus3]\# vim install_node_exportes.sh
#!/bin/bash
#批量安装node_exporter
soft_dir=/root/soft
if [ ! -e $soft_dir ];then
mkdir $soft_dir
fi
netstat -lnpt | grep 9100
if [ $? -eq 0 ];then
use=`netstat -lnpt | grep 9100 | awk -F/ '{print $NF}'`
echo "9100端口已经被占用,占用者是 $use"
exit 1
fi
cd $soft_dir
wget http://192.168.16.106:888/prometheus/node_exporter-1.0.1.linux-amd64.tar.gz
tar xf node_exporter-1.0.1.linux-amd64.tar.gz
mv node_exporter-1.0.1.linux-amd64 /usr/local/node_exporter
cat <<EOF >/usr/lib/systemd/system/node_exporter.service
[Unit]
Description=https://prometheus.io
[Service]
Restart=on-failure
ExecStart=/usr/local/node_exporter/node_exporter --collector.systemd --collector.systemd.unit-whitelist=(docker|kubelet|node_exporter).service
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable node_exporter
systemctl restart node_exporter
netstat -lnpt | grep 9100
if [ $? -eq 0 ];then
ehoc "node_eporter install finish..."
fi
5.2.对k8s的node进行执行node_exporter脚本
在这里下载脚本用就行了
[root@k8s-node1 ~]\# wget http://192.168.16.106:888/install_node_exportes.sh
[root@k8s-node1 ~]\# sh install_node_exportes.sh
[root@k8s-node1 ~]\# netstat -lnpt | grep 9100
tcp6 0 0 :::9100 :::* LISTEN 14906/node_exporter
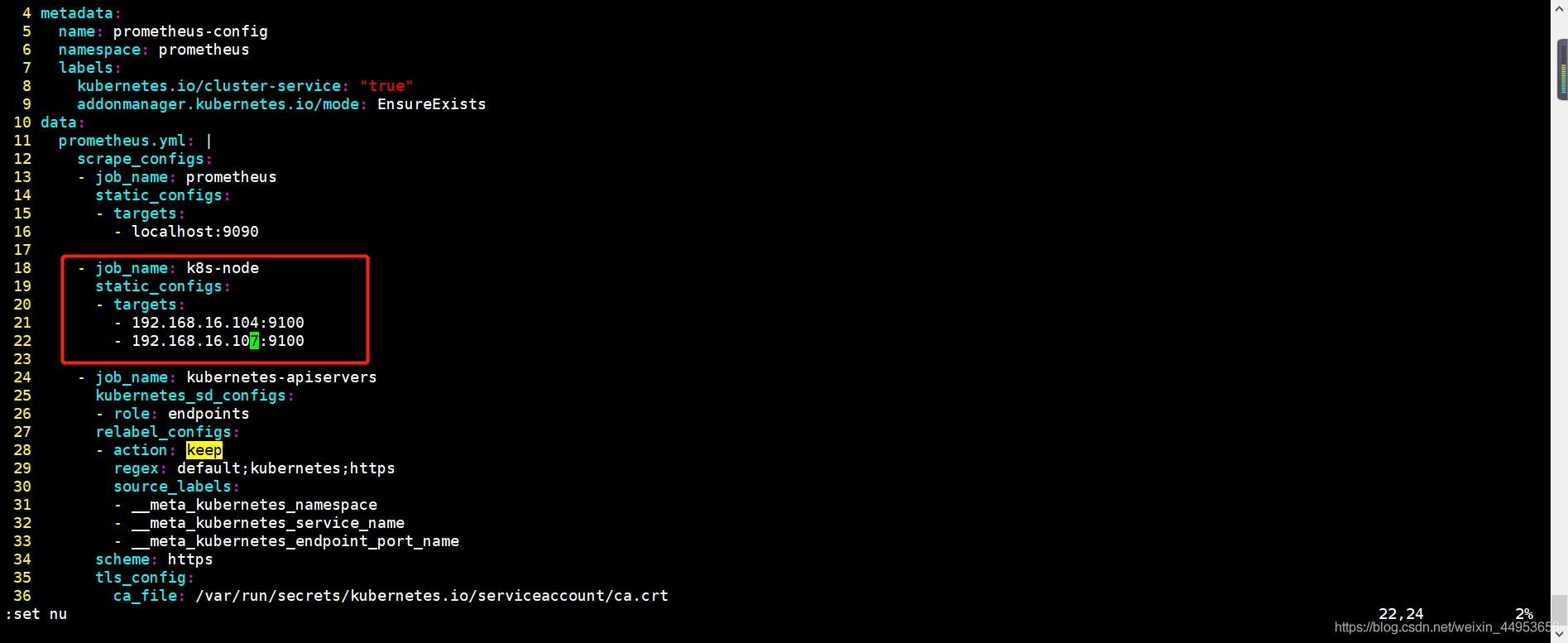
5.3.在prometheus的configmap资源中增加node节点配置
[root@k8s-master ~/k8s/prometheus3]\# vim prometheus-configmap.yaml
- job_name: k8s-node
static_configs:
- targets:
- 192.168.16.104:9100
- 192.168.16.107:9100
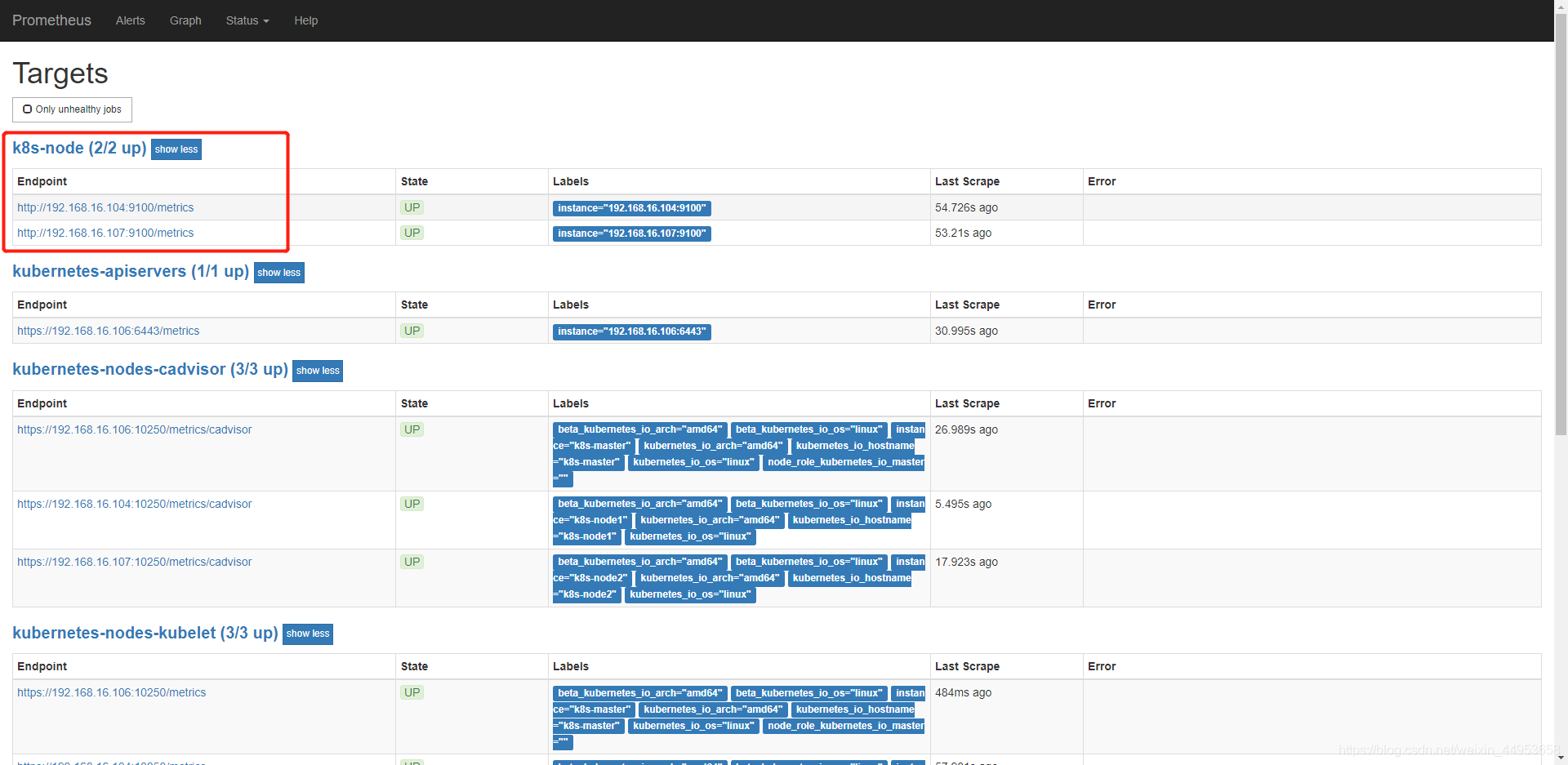
更新配置
更新完配置,prometheus页面会立马显示,因此每当configmap一修改,prometheus容器就会重载
[root@k8s-master ~/k8s/prometheus3]\# kubectl apply -f prometheus-configmap.yaml
configmap/prometheus-config created
成功添加node监控
5.4.导入k8s node主机监控模板
node监控:9276
填写信息
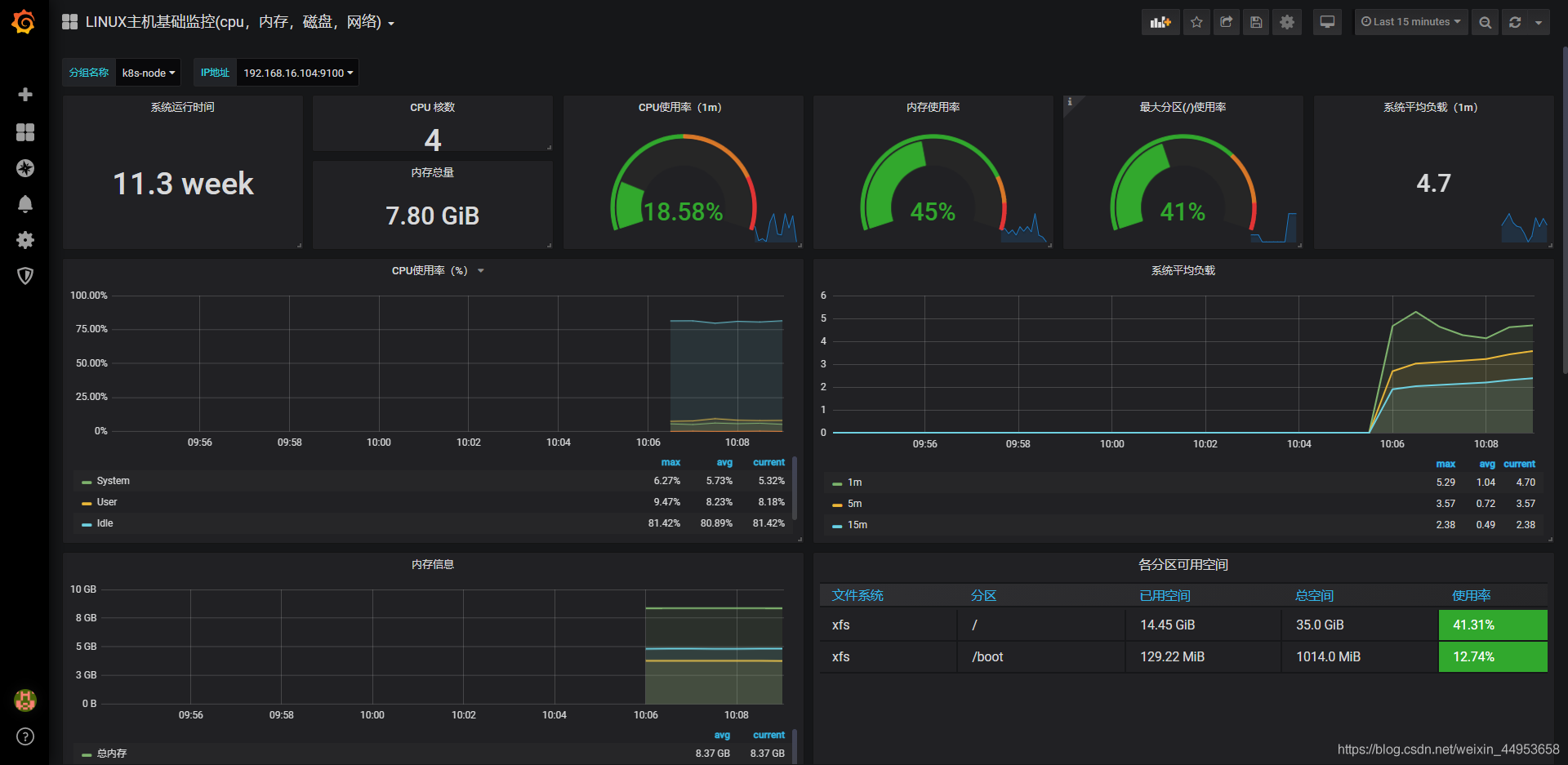
 查看图形
查看图形
6.k8s使用kube-state-metrics-监控资源状态
6.1.创建rbac资源
[root@k8s-master ~/k8s/prometheus3]\# kubectl create kube-state-metrics-rbac.yaml
6.2.创建deployment资源
deployment资源里面结合了configmap资源
需要把镜像的地址修改成lizhenliang/kube-state-metrics:v1.8.0、lizhenliang/addon-resizer:1.8.6
[root@k8s-master ~/k8s/prometheus3]\# kubectl create -f kube-state-metrics-deployment.yaml

6.3.创建service资源
[root@k8s-master ~/k8s/prometheus3]\# kubectl create -f kube-state-metrics-service.yaml
6.4.资源准备就绪
[root@k8s-master ~/k8s/prometheus3]\# kubectl get all -n kube-system | grep kube-state

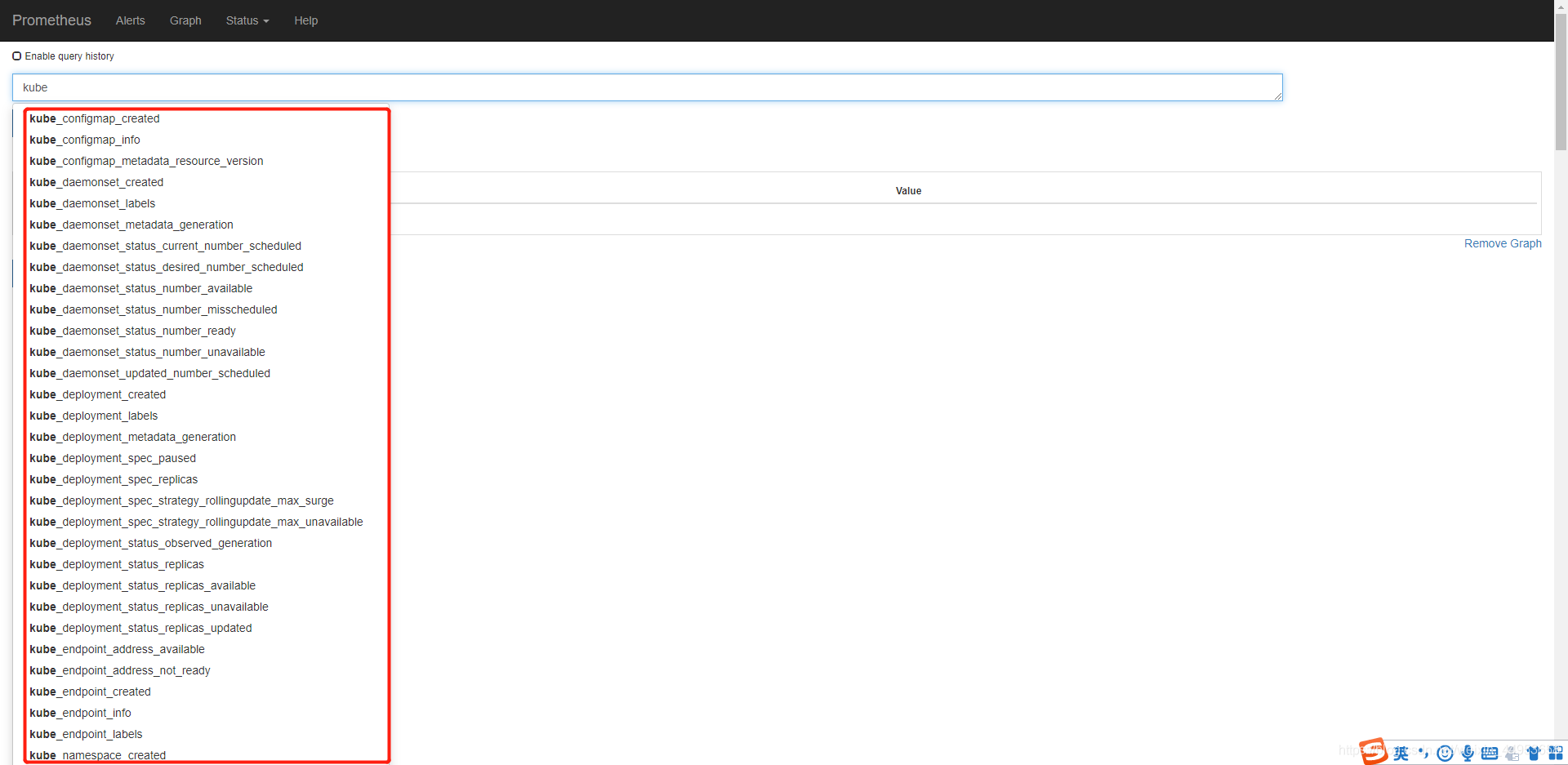
6.5.在prometheus查看是否获取监控指标
安装完kube-state-metrics之后,直接就可以在prometheus上查询监控指标,都是以kube开头的
6.6.导入k8s 资源状态模板
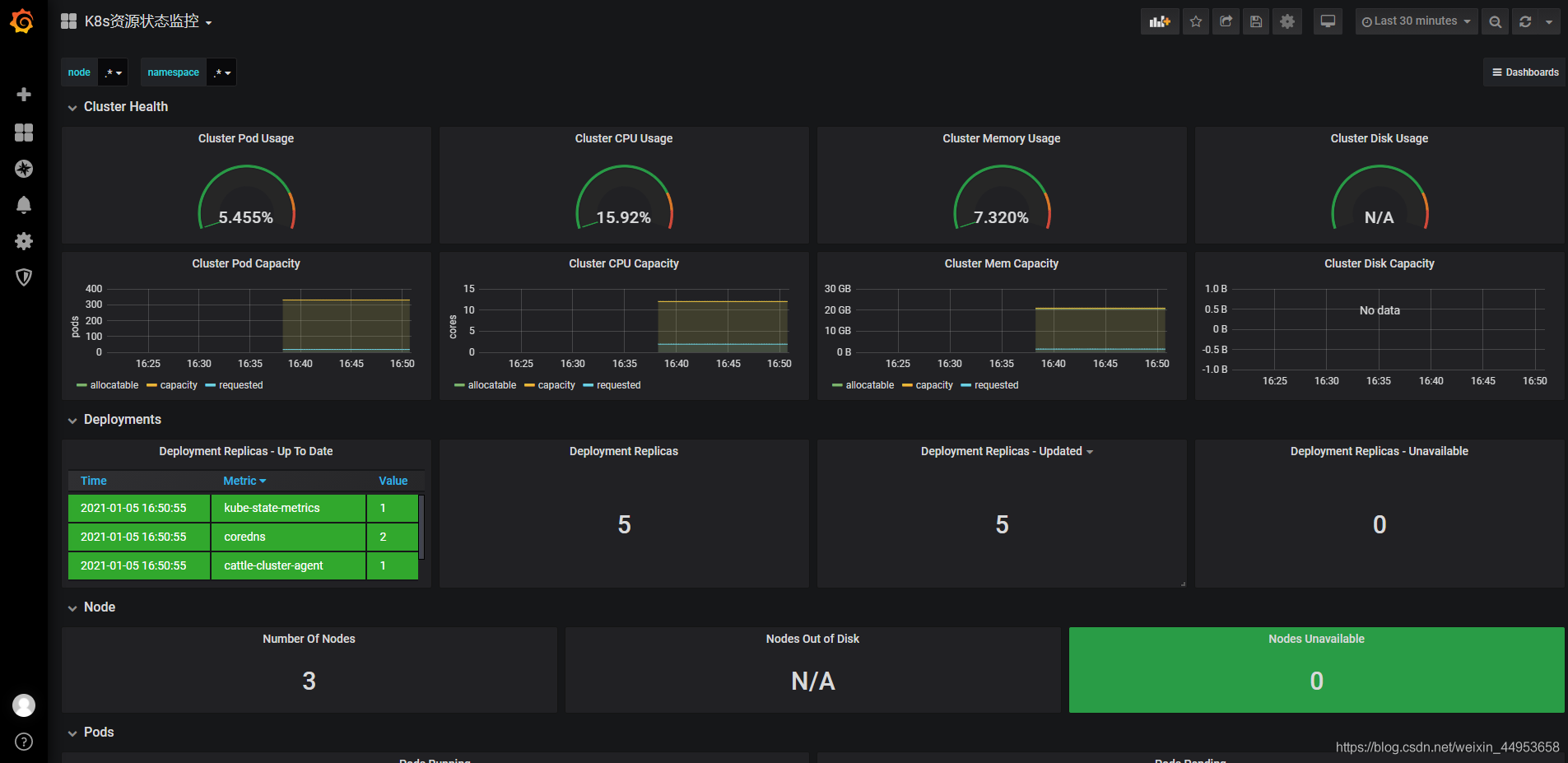
资源状态监控:6417
查看图形,也是有很多监控不到
7.在k8s中部署alertmanager实现告警系统
7.1.创建alertmanager-pv-pvc资源
1.编写yaml
[root@k8s-master ~/k8s/prometheus3]\# vim alertmanager-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: alertmanager-data
namespace: alertmanager
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: EnsureExists
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: "2Gi"
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-alertmanager-data
namespace: alertmanager
spec:
capacity:
storage: 2Gi
accessModes:
- ReadWriteOnce
nfs:
path: /data/prometheus/alertmanager
server: 192.168.16.105
2.创建
[root@k8s-master ~/k8s/prometheus3]\# kubectl create -f alertmanager-pvc.yaml
persistentvolumeclaim/alertmanager created
persistentvolume/pv-alertmanager-data create
7.2.创建alertmanager-cm资源增加微信告警配置
增加微信报警
1.增加微信告警配置
[root@k8s-master ~/k8s/prometheus3]\# vim alertmanager-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager-config
namespace: alertmanager
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: EnsureExists
data:
alertmanager.yml: |
global:
resolve_timeout: 5m
receivers:
- name: 'wechat'
wechat_configs:
- corp_id: 'ww48f74fc8ed3a07ba'
to_party: '1'
agent_id: '1000003'
api_secret: 'j3ocaGJJM7KejlqzBIJ38b6D6t9QhqlIAh7k4fA1cT0'
send_resolved: true
route:
group_interval: 1m
group_wait: 10s
receiver: wechat
repeat_interval: 1m
2.创建资源
[root@k8s-master ~/k8s/prometheus3]\# kubectl create -f alertmanager-configmap.yaml
configmap/alertmanager-config created
7.3.创建alertmanager-deployment资源
[root@k8s-master ~/k8s/prometheus3]\# kubectl create -f alertmanager-deployment.yaml
deployment.apps/alertmanager created
7.4.创建alertmanager-service资源
[root@k8s-master ~/k8s/prometheus3]\# kubectl create -f alertmanager-service.yaml
service/alertmanager created
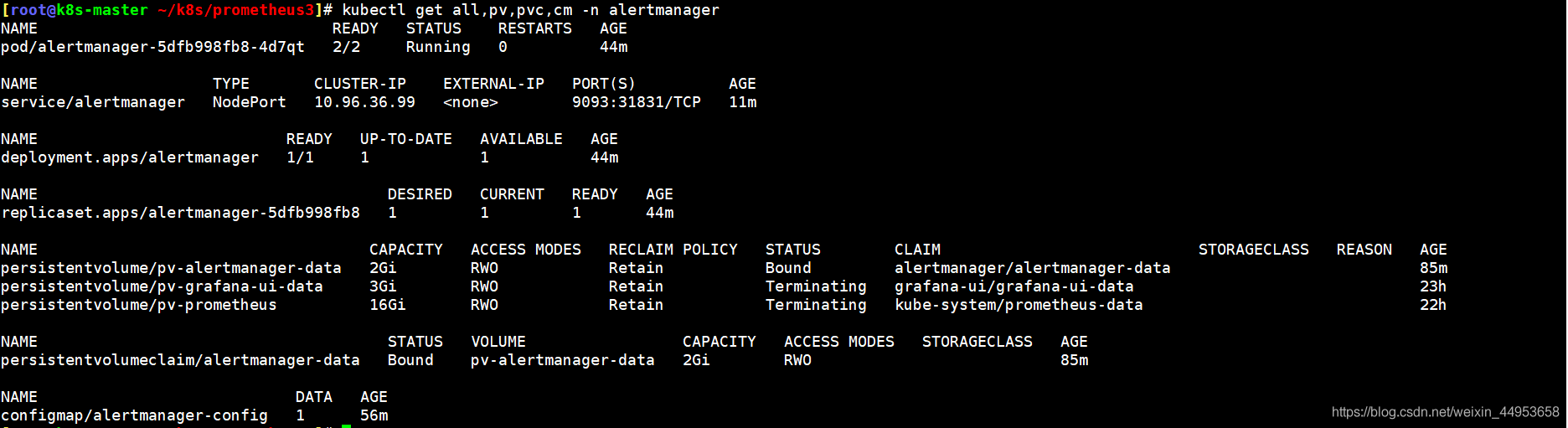
7.5查看alertmanager所有资源
[root@k8s-master ~/k8s/prometheus3]\# kubectl get all,pv,pvc,cm -n alertmanager
7.6.访问alertmanager
任意node节点+31831端口即可
配置文件已经支持微信报警
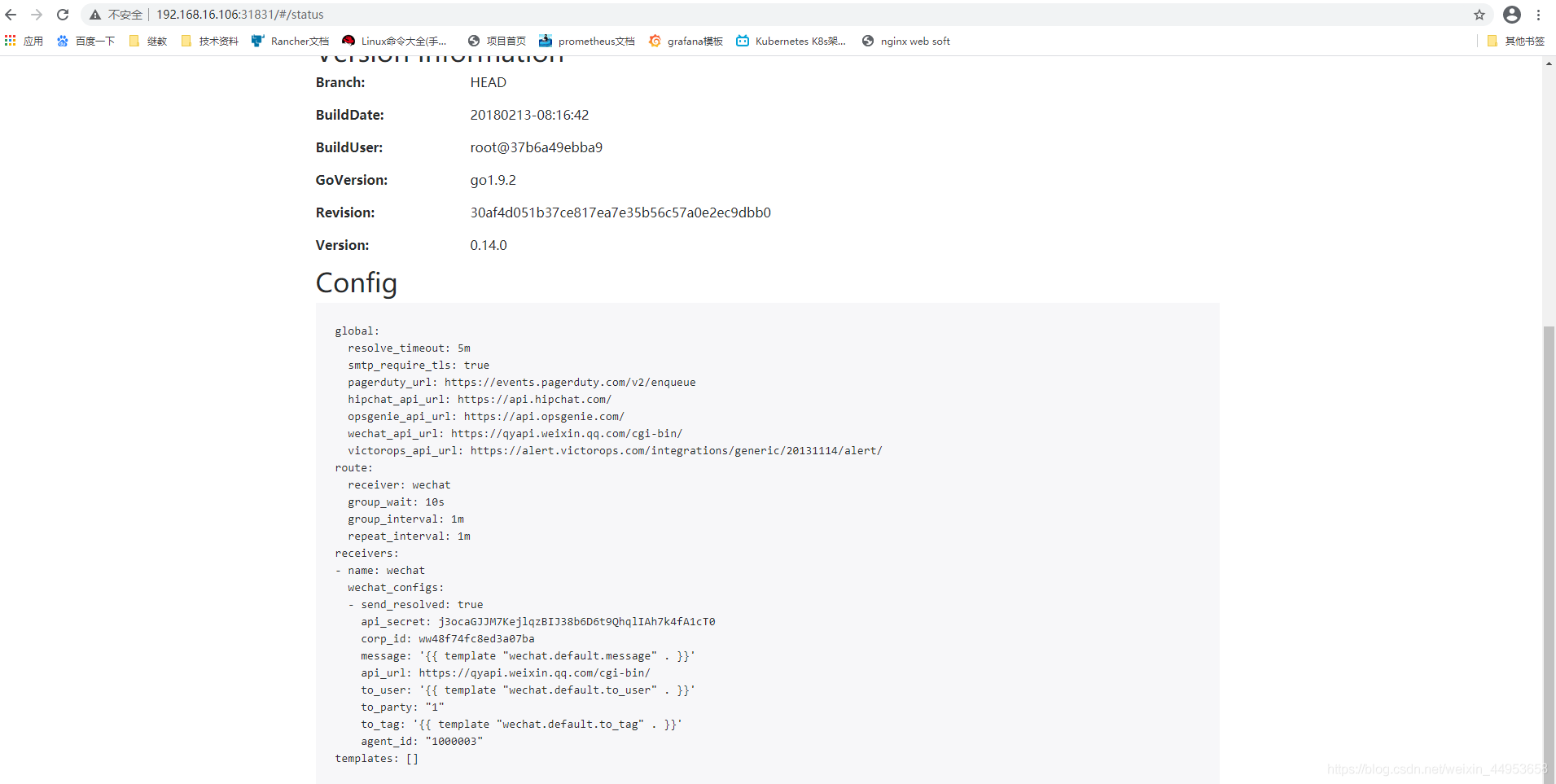
8.配置alertmanager实现k8s告警系统
8.1.在NFS上准备两个告警规则文件
我们对于告警规则文件不采用configmap的方式而是采用pv、pvc的方式把告警规则挂载到容器里
1.在nfs上创建pv存储路径
[root@nfs ~]\# mkdir /data/prometheus/rules
[root@nfs ~]\# chmod -R 777 /data
[root@nfs ~]\# cd /data/prometheus/rules
2.准备主机宕机的告警规则文件
[root@nfs rules]\# vim hostdown.yml
groups:
- name: general.rules
rules:
- alert: 主机宕机
expr: up == 0
for: 1m
labels:
serverity: error
annotations:
summary: "主机 {{ $labels.instance }} 停止工作"
description: "{{ $labels.instance }} job {{ $labels.job }} 已经宕机5分钟以上!"
3.准备主机基础监控告警规则文件
[root@nfs rules]\# vim node.yml
groups:
- name: node.rules
rules:
- alert: NodeFilessystemUsage
expr: 100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs",mountpoint="/"} / node_filesystem_size_bytes{fstype=~"ext4|xfs",mountpoint="/"} *100) > 80
for: 1m
labels:
serverity: warning
annotations:
summary: "主机 {{ $labels.instance }} : {{ $labels.mountpoint }} 磁盘使用率过高"
description: "{{ $labels.instance }} : {{ $labels.mountpoint }} 磁盘使用率超过80% (当前值: {{ $value }}) "
- alert: NodeMemoryUsage
expr: 100 - ((node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100) > 80
for: 1m
labels:
serverity: warning
annotations:
summary: "主机 {{ $labels.instance }} 内存使用率过高"
description: "{{ $labels.instance }} 内存使用率超过80% (当前值: {{ $value }}) "
- alert: NodeCpuUsage
expr: 100 - (avg(irate(node_cpu_seconds_total{mode='idle'}[5m])) by (instance) *100) > 80
for: 1m
labels:
serverity: warning
annotations:
summary: "主机 {{ $labels.instance }} CPU使用率过高"
description: "{{ $labels.instance }} CPU使用率超过80% (当前值: {{ $value }}) "
8.2.编写rules告警规则的pv、pvcyaml文件
1.编写资源文件
[root@k8s-master ~/k8s/prometheus3]\# vim prometheus-rules-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: prometheus-rules
namespace: kube-system
labels:
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: "2Gi"
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-prometheus-rules
spec:
capacity:
storage: 2Gi
accessModes:
- ReadWriteOnce
nfs:
path: /data/prometheus/rules
server: 192.168.16.105
2.创建资源
[root@k8s-master ~/k8s/prometheus3]\# kubectl create -f prometheus-rules-pvc.yaml
persistentvolumeclaim/prometheus-rules created
persistentvolume/pv-prometheus-rules created
8.3.修改prometheus的statefulset资源集成rules
在prometheus的statefulset资源中增加rules的pvc挂载路径
[root@k8s-master ~/k8s/prometheus3]\# vim prometheus-statefulset-static-pv.yaml
volumeMounts:
- name: config-volume
mountPath: /etc/config
- name: prometheus-rules
mountPath: /etc/config/rules
- name: prometheus-data
mountPath: /data
subPath: ""
terminationGracePeriodSeconds: 300
volumes:
- name: config-volume
configMap:
name: prometheus-config
- name: prometheus-rules
persistentVolumeClaim:
claimName: prometheus-rules
- name: prometheus-data
persistentVolumeClaim:
claimName: prometheus-data
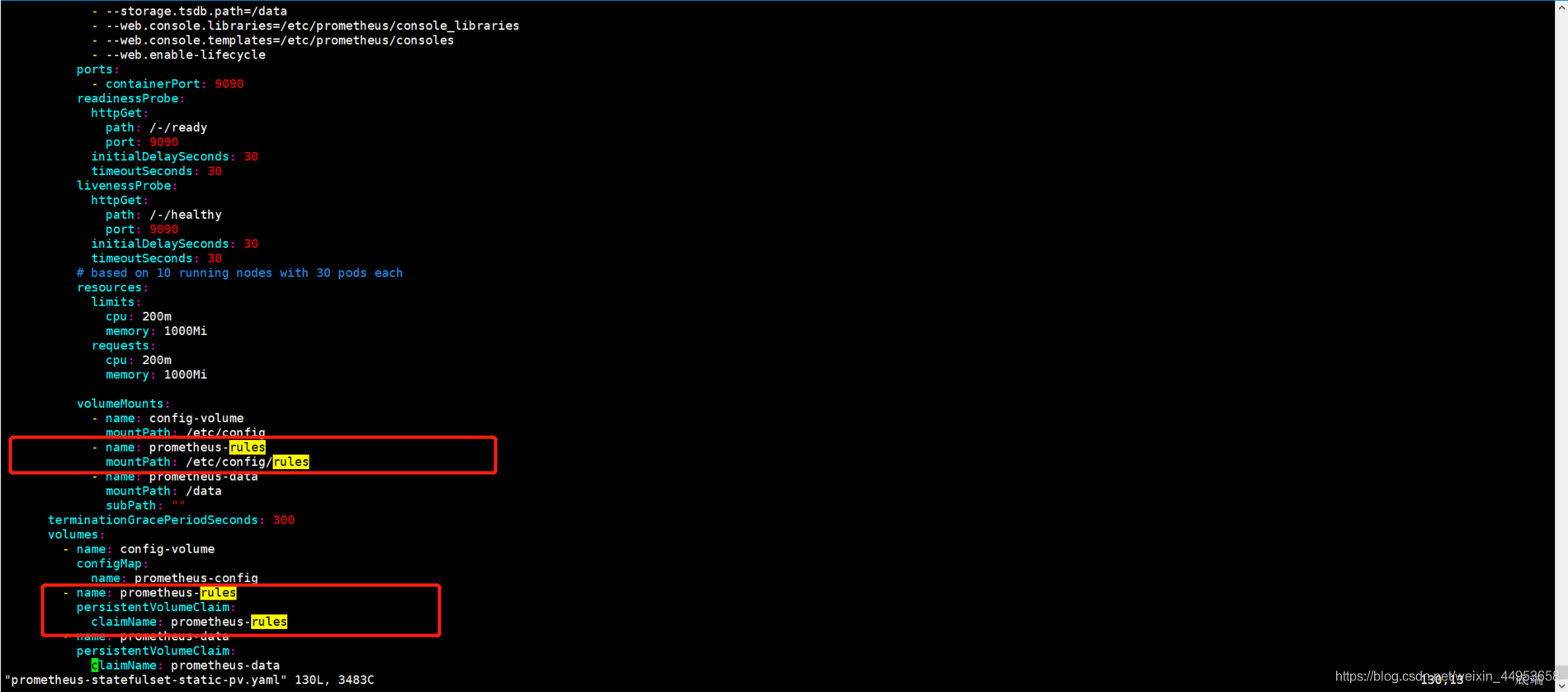
8.4.更新prometheus-statefulset资源
[root@k8s-master ~/k8s/prometheus3]\# kubectl apply -f prometheus-statefulset-static-pv.yaml
8.5.修改prometheus-configmap资源配置alertmanager地址
1.修改配置增加alertmanager地址
[root@k8s-master ~/k8s/prometheus3]\# vim prometheus-configmap.yaml
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.16.106:31831
2.更新资源
[root@k8s-master ~/k8s/prometheus3]\# kubectl apply -f prometheus-configmap.yaml
configmap/prometheus-config configured
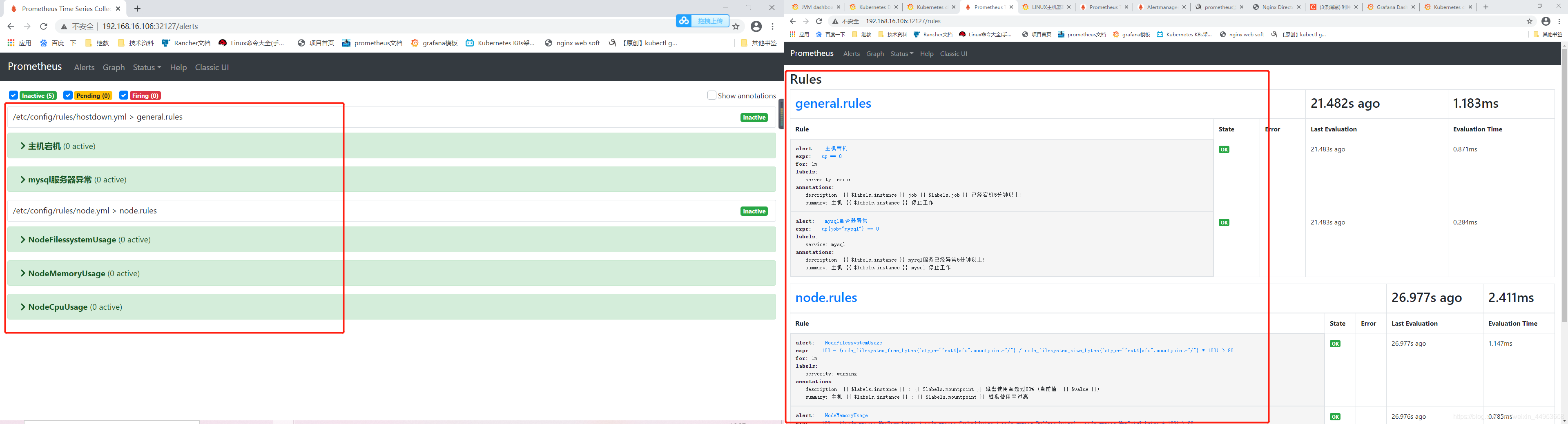
8.5.查看页面是否增加告警规则
已经成功填加rules告警规则
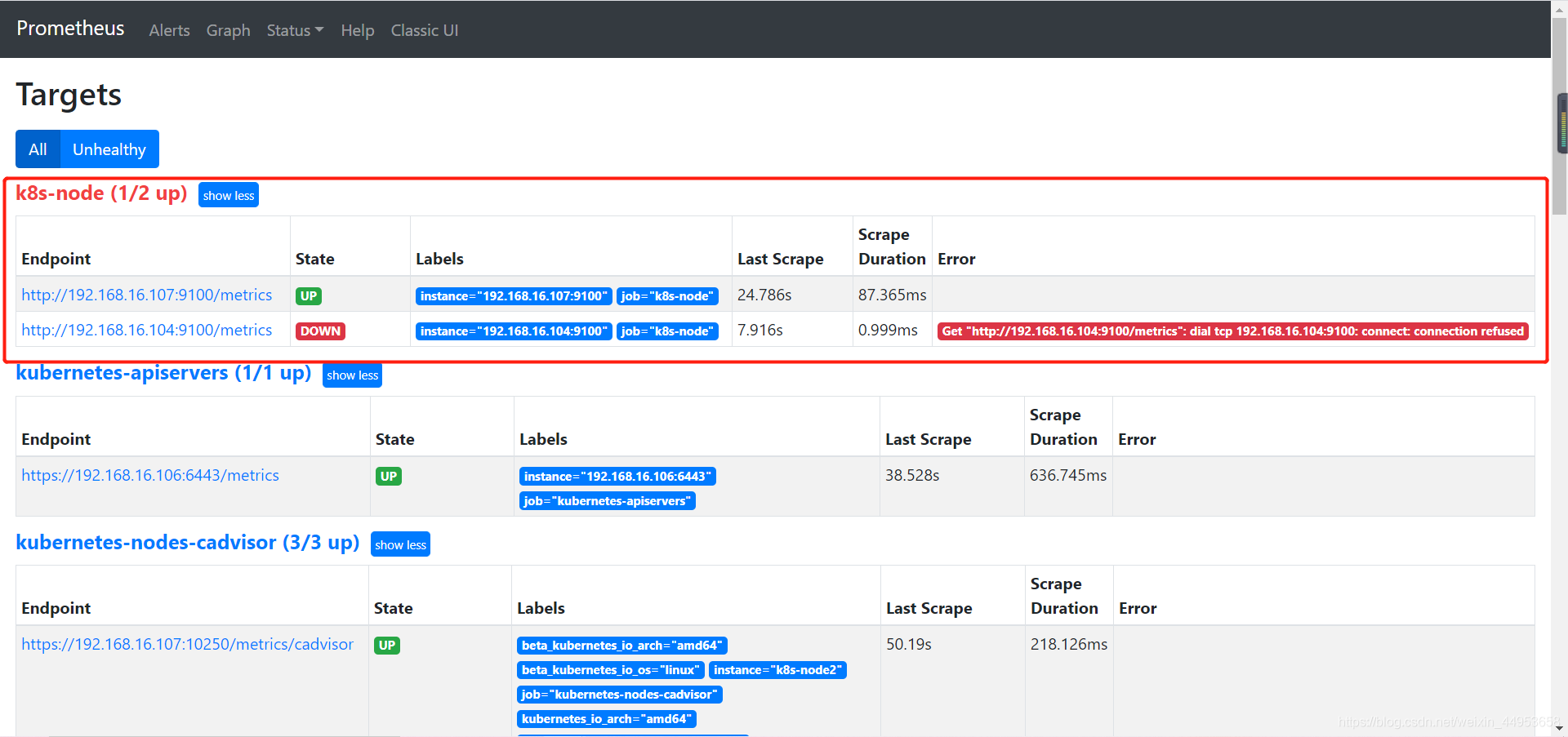
8.6.模拟node主机宕机并查看微信告警内容
模拟触发告警
将任意一个node节点的node_exporter停掉即可
[root@k8s-node1 ~]\# systemctl stop node_exporter
告警已经产生
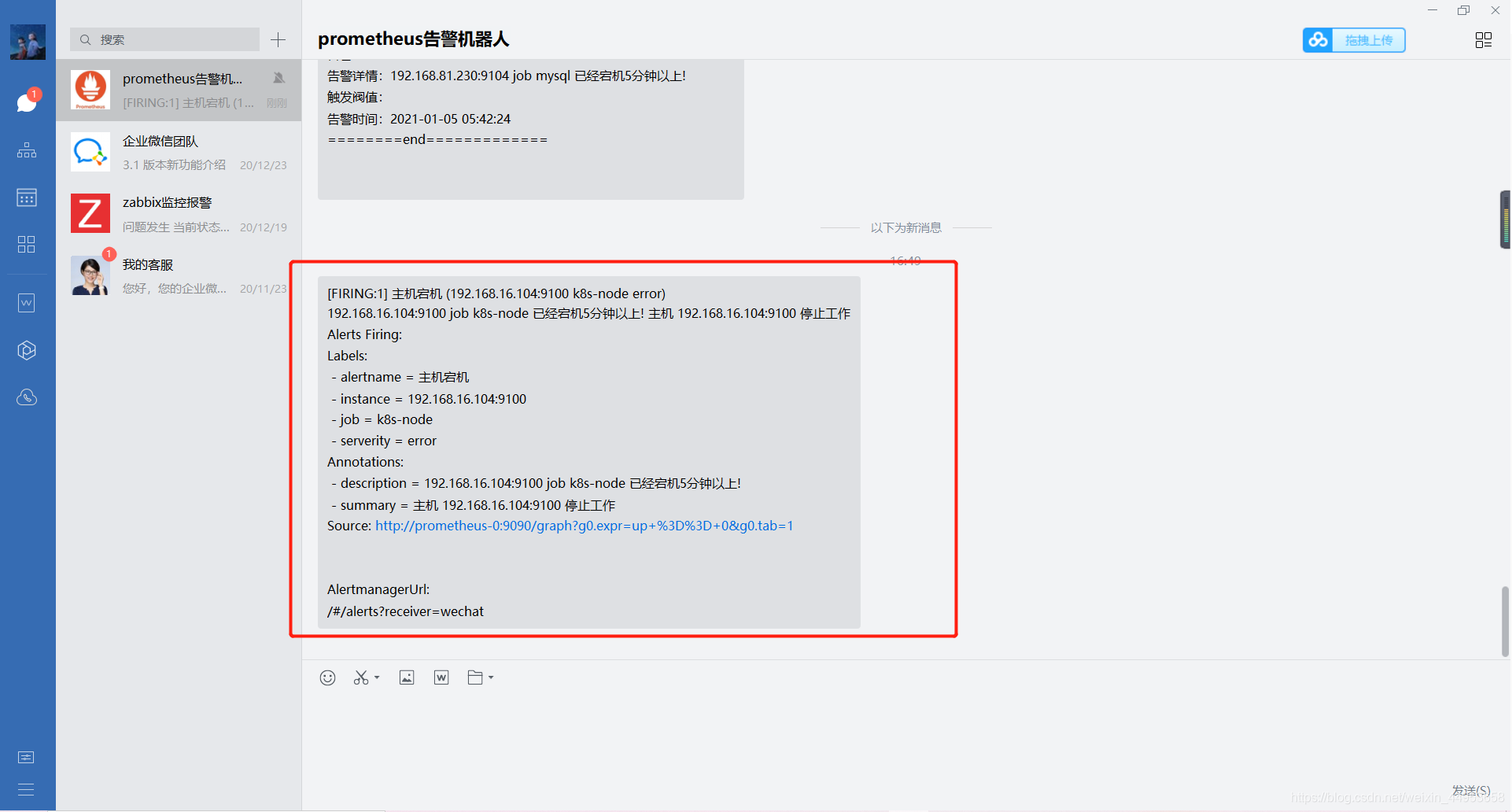
告警消息已经发送
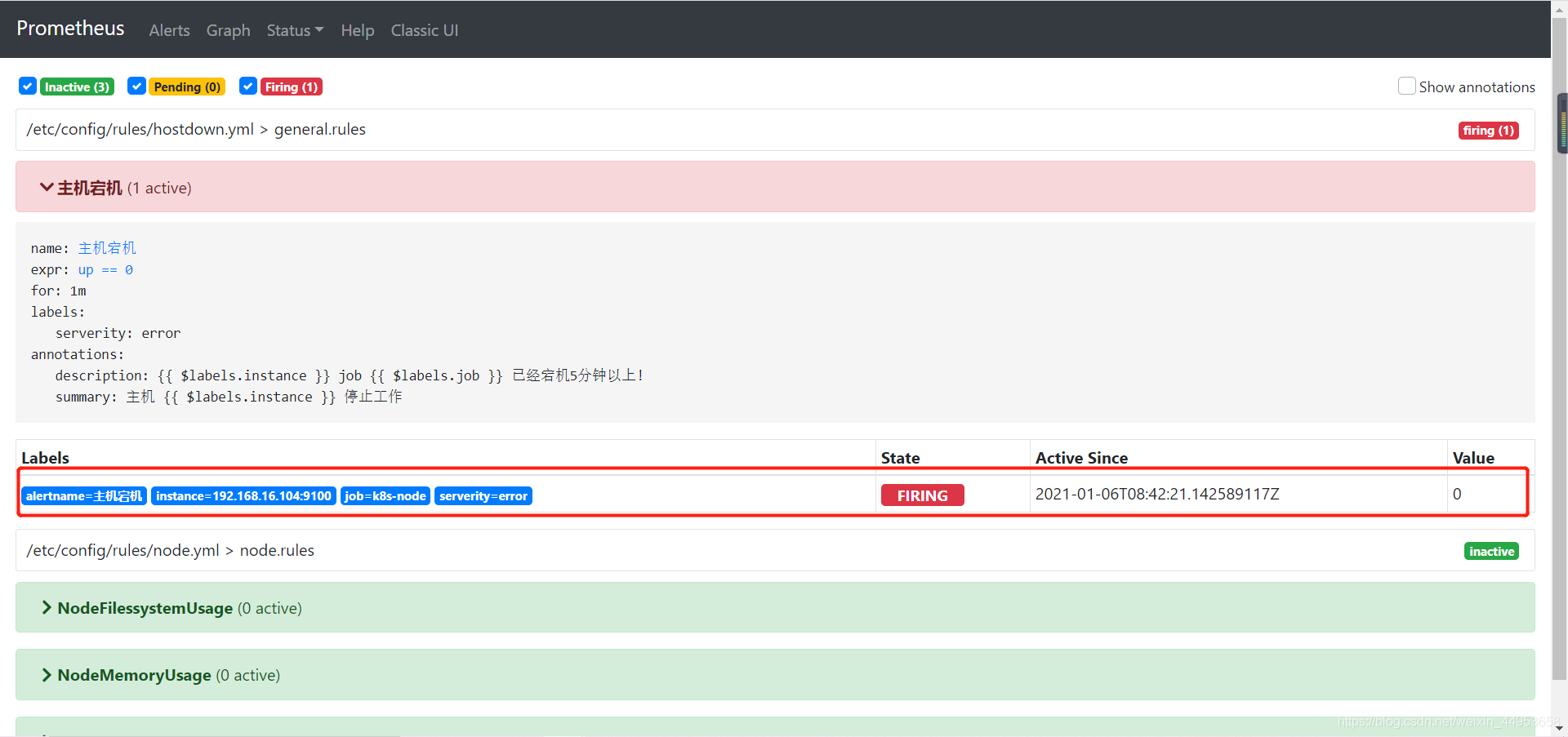
查看告警内容
已经成功收到告警,k8s监控系列篇到此结束
该文章为转载内容,仅做备份私人学习使用,原文:https://jiangxl.blog.csdn.net/article/details/112283085